
最近、サーバーのアクセスログに「GPTBot」や「ClaudeBot」といった見慣れない名前が増えていませんか?これらは、ChatGPTやClaudeなどのAIがウェブサイトの情報を読み取るための「AIクローラー」です。
「自分のコンテンツが勝手にAIの学習に使われるのは困る」という声がある一方で、「AI検索からの流入を逃したくない」という意見もあります。
果たして、自分のサイトではAIクローラーを許可すべきなのか、それともブロックすべきなのか?
今回は、2026年現在のサーバー設定におけるAIクローラーの扱いについて、メリット・デメリットと具体的な設定方法を解説します。
1. AIクローラーをブロックするかどうかの判断基準
結論から言うと
コンテンツを守りたいならブロック
AI時代のSEOを狙うなら許可
という選択になります。
AIクローラーを【ブロック】したほうが良いケース
- 独自のノウハウや作品を守りたい
有料級の記事や独自調査の結果を、AIにタダで「要約」されて満足されたくない場合。 - サーバー負荷を抑えたい:
クローラーの巡回が激しすぎて、一般ユーザーの閲覧速度が落ちている場合。 - 無断学習に反対の立場である:
著作権や情報の二次利用に対して厳格に管理したい場合。
AIクローラーを【許可】したほうが良いケース
- AI検索(SearchGPTやPerplexityなど)で引用されたい:
AIが回答を作成する際、ソースとして自分のサイトを紹介してほしい場合。 - ブランドの正確な情報を広めたい:
AIが古い情報や間違った情報を学習しないよう、常に最新の公式情報を読み取らせたい場合。
2. 主要なAIクローラーと役割一覧
現在、特に対策を検討すべき主要なボットは以下の通りです。
| ボット名 | 運営元 | 主な役割 |
| GPTBot | OpenAI | ChatGPTの学習および回答精度の向上 |
| ClaudeBot | Anthropic | AIモデル「Claude」の学習用データ収集 |
| CCBot | Common Crawl | AI学習に広く使われるオープンなデータ収集 |
| Google-Extended | GeminiなどのAI学習への利用(検索とは別枠) |
3. 具体的な設定方法(robots.txt)
AIクローラーの制御は、サイトのルートディレクトリにある robots.txt ファイルで行います。
全ての主要AIボットをブロックする場合
AIによる無断学習を包括的に防ぎたい場合の記述例です。
Plaintext
# OpenAI (ChatGPT)
User-agent: GPTBot
Disallow: /
# Anthropic (Claude)
User-agent: ClaudeBot
Disallow: /
# Common Crawl (AI学習データセット)
User-agent: CCBot
Disallow: /
# Google AI学習用 (Google検索には影響しません)
User-agent: Google-Extended
Disallow: /
特定のディレクトリだけを保護する場合
「記事一覧は読ませてもいいが、特定のノウハウ集だけは守りたい」という場合は以下のように記述します。
Plaintext
User-agent: GPTBot
Disallow: /secret-tips/
[!CAUTION]
注意:Google検索への影響について
Googlebot自体をブロックしてしまうと、Googleの検索結果から消えてしまいます。AI学習だけを拒否したい場合は、必ずGoogle-Extendedの方を指定しましょう。
4. 【実践編】Xserver(エックスサーバー)での設定手順
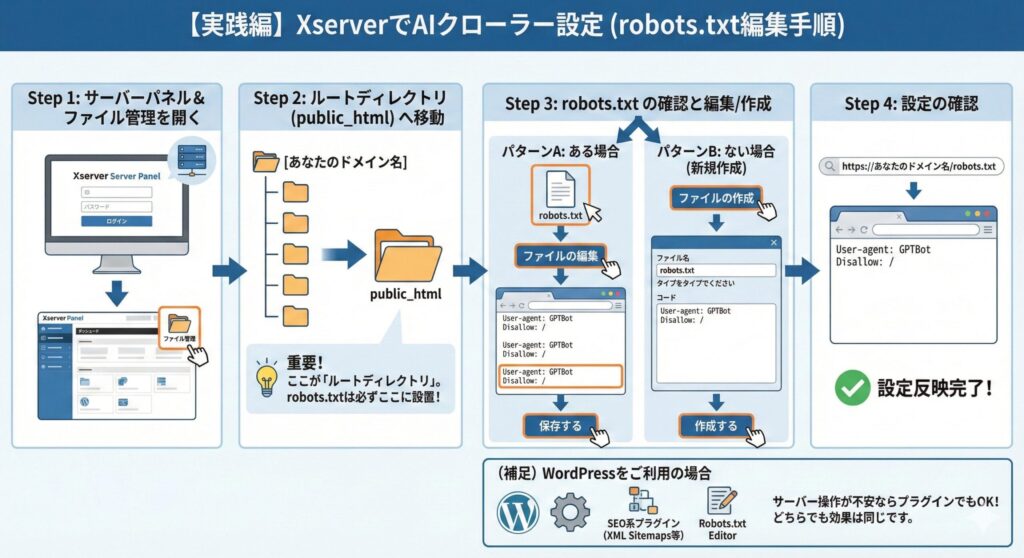
国内で利用者の多い「エックスサーバー」をお使いの方向けに、具体的な設定手順を解説します。
エックスサーバーでは、わざわざFTPソフトを用意しなくても、サーバーパネルから直接アクセスできる「ファイル管理」ツールを使って簡単に robots.txt を編集・作成できます。
手順1:サーバーパネルにログインし「ファイル管理」を開く
- エックスサーバーの「サーバーパネル」にログインします。
- メニュー内にある 「ファイル管理」 をクリックします。(通常、画面の右上あたり、または「ホームページ」カテゴリー内にあります)
手順2:対象ドメインのルートディレクトリ(public_html)へ移動
ファイルマネージャーの画面が開いたら、以下の順序でフォルダをダブルクリックして進んでください。
- 設定したい [あなたのドメイン名] のフォルダを開きます。
- その中にある 「public_html」 というフォルダを開きます。
[!NOTE] ここが重要!
「ルートディレクトリ」とは? この 「public_html」 が、インターネット上に公開されている場所の最上層(ルートディレクトリ)になります。
robots.txtは必ずこの場所に設置する必要があります。
手順3:robots.txt の確認と編集(または新規作成)
「public_html」フォルダの中に、すでに robots.txt というファイルがあるかどうかを確認します。
パターンA:すでに「robots.txt」がある場合
robots.txtファイルをクリックして選択状態にします。- 上部メニューにある 「ファイルの編集」 をクリックします。
- 編集画面が開きます。既存の内容は消さずに、末尾に 改行を入れて、この記事の「2. 具体的な設定方法(robots.txt)」で紹介したコード(ブロックしたいボットの記述)を貼り付けます。
- 「保存する」 をクリックして完了です。
パターンB:「robots.txt」がない場合(新規作成)
- 上部メニューにある 「ファイルの作成」 をクリックします。
- ファイル名の欄に半角英字で
robots.txtと入力します。 - 下の大きな入力欄に、この記事の「2. 具体的な設定方法(robots.txt)」で紹介したコードをコピーして貼り付けます。
- 「作成する」 をクリックして完了です。
手順4:設定が反映されたか確認する
設定が完了したら、ブラウザのアドレスバーに以下のように入力してアクセスしてみましょう。
画面に、あなたが記述した内容がそのまま表示されれば、正しく設置できています。
(補足)WordPressをご利用の場合
WordPressでサイトを構築している場合、直接サーバーのファイルを触るのが怖いと感じるかもしれません。その場合はプラグインを利用するのも一つの手です。
- 「XML Sitemaps」などのSEO系プラグイン:
多くのSEOプラグインにはrobots.txtを編集する機能が標準でついています。 - 「Robots.txt Editor」:
その名の通り、編集専用のシンプルなプラグインです。
どちらの方法でも効果は同じですので、ご自身のスキルに合わせてやりやすい方法を選んでください。
まとめ:あなたのサイトはどうすべき?
最後に、タイプ別の推奨設定をまとめます。
- 個人のブログ・アフィリエイトサイト:
AI検索からの流入(引用)を期待するなら「許可」で様子見。 - 企業サイト・公式HP:
正確な情報をAIに認識させるため「許可」が推奨されますが、サーバー負荷が気になるなら制限を。 - クリエイター・専門メディア: コンテンツが最大の資産であるため、現状は「ブロック」して権利を守るのが主流です。
AIクローラーの動向は非常に速いため、一度設定して終わりではなく、半年に一度程度はアクセスログを確認して設定を見直すことをおすすめします。

